Z Skrypty dla studentów Ekonofizyki UPGOW
Wprowadzenie do metod numerycznych
Metody numeryczne to dziedzina wiedzy zajmująca się problemami obliczeniowymi i konstrukcją algorytmów rozwiązywania zadań matematycznych. Najczęściej, zadania obliczeniowe postawione są w dziedzinie rzeczywistej (lub zespolonej) i dlatego mówimy o zadaniach obliczeniowych matematyki ciągłej (w odróżnieniu od matematyki dyskretnej).
Zadania metod numerycznych
Aby w ogóle mówić w problemie obliczeniowym, musimy najpierw
- określić dane problemu i cel obliczeń, czyli dokładnie sformułować zadanie w języku matematyki,
- określić środki obliczeniowe dzięki którym chcemy osiągnąć cel,
- dla analizy zadania i sposobów jego rozwiązania wygodnie jest zdefiniować klasę rozpatrywanych danych oraz model obliczeniowy w obrębie którego będą działać nasze algorytmy.
Wbrew dość powszechnej opinii nie jest prawdą, że głównym przedmiotem metod numerycznych jest badanie wpływu błędów zaokrągleń na wynik. Raczej, głównym celem metod numerycznych jest konstrukcja optymalnych (w jasno określonym sensie, np. pod względem wymaganej liczby operacji, lub pod względem ilości niezbędnej informacji, czy też pod względem dokładności uzyskiwanego wyniku) algorytmów rozwiązywania konkretnych zadań matematycznych.
Uwaga
Nasz przedmiot ma różne wcielenia i z tego powodu czasem nosi inne nazwy, w zależności od tego, na jaki aspekt metod obliczeniowych jest położony największy nacisk.
- metody numeryczne --- główny nacisk idzie na aspekty algorytmiczne;
- analiza numeryczna --- przede wszystkim badanie właściwości algorytmów, ich optymalności oraz wpływu arytmetyki zmiennopozycyjnej na jakość uzyskanych wyników;
- matematyka obliczeniowa --- głównie teoretyczna analiza możliwości taniej i dokładnej aproksymacji rozwiązań zadań matematycznych;
- obliczenia naukowe --- nacisk na praktyczne zastosowania metod numerycznych, symulacje, realizacje na komputerach o dużej mocy obliczeniowej.
Oczywiście, granice podziału nie są ostre i najczęściej typowy wykład z tego przedmiotu stara się pokazać pełne spektrum zagadnień z nim związanych. Tak będzie i w naszym przypadku.
Model obliczeniowy
Tworząc i analizując algorytmy, jakie będą pojawiać w naszym wykładzie, będziemy posługiwać się pewnym uproszczonym modelem obliczeń, dzięki czemu będziemy mogli skoncentrować się na esencji algorytmu, bez detali implementacyjnych --- zostawiając je na inną okazję (dobra implementacja konkretnego algorytmu może być sama w sobie interesującym wyzwaniem programistycznym; często bywa, że dobre implementacje, nawet prostych algorytmów numerycznych, są mało czytelne).
Aby zdefiniować nasz model obliczeniowy, posłużymy się pojęciem programu. Zastosujemy przy tym notację podobną do tej z języka programowania C.
Program składa się z deklaracji, czyli opisu obiektów, których będziemy używać, oraz z poleceń (instrukcji), czyli opisu akcji, które będziemy wykonywać.
Dostępnymi obiektami są stałe i zmienne typu
całkowitego (int),
rzeczywistego (float i double). Typ logiczny symulujemy tak jak w
C wartościami zero-jedynkowymi typu całkowitego.
Zmienne jednego typu mogą być grupowane w wektory albo tablice.
Widzimy więc, że podstawowe algorytmy numeryczne będą bazować na mało
skomplikowanych typach danych. Również nieskomplikowane będą instrukcje naszego
modelowego języka. Dążenie do prostoty (ale nie za wszelką cenę) jest charakterystyczne dla numeryki. Typowe jest zastępowanie skomplikowanych tablic rekordów prostszymi macierzami, eleganckich rekurencji --- zwykłymi pętlami działającymi na danych w miejscu. Jedną z myśli przewodnich numeryki jest bowiem szybkość, a rezygnacja z barokowych konstrukcji językowych jest zgodna z filozofią architektury procesora RISC: efektywność przez prostotę.
(Na pewno zastanawiasz się teraz, jaka jest druga myśl przewodnia numeryki. To dokładność.)
Podstawienie
Najprostsza z instrukcji, bez której nie można się obejść:
z = <math>\displaystyle {\cal W}</math>;
Tutaj \(\displaystyle z\) jest zmienną, a \(\displaystyle {\cal W}\) jest wyrażeniem o wartościach tego samego typu co \(\displaystyle z\). Jest to polecenie proste.
Wyrażeniem jest pojedyncza stała lub zmienna, albo złożenie skończonej liczby operacji elementarnych na wyrażeniach. Operacje elementarne to:
- arytmetyczno--arytmetyczne
- \(\displaystyle x\mapsto -x\), \(\displaystyle (x,y)\mapsto x+y\),
\(\displaystyle (x,y)\mapsto x-y\), \(\displaystyle (x,y)\mapsto x*y\), \(\displaystyle (x,y)\mapsto x/y, y\ne 0\), gdzie \(\displaystyle x,y\) są stałymi lub zmiennymi liczbowymi,
- arytmetyczno--logiczne
- \(\displaystyle (x,y)\mapsto x<y\),
\(\displaystyle (x,y)\mapsto x\le y\), \(\displaystyle (x,y)\mapsto x=y\), \(\displaystyle (x,y)\mapsto x\ne y\), gdzie \(\displaystyle x,y\) są stałymi lub zmiennymi liczbowymi,
- logiczno--logiczne
- \(\displaystyle p\mapsto\,\sim \,p\),
\(\displaystyle (p,q)\mapsto p\, \wedge \,q\), \(\displaystyle (p,q)\mapsto p\, \vee \,q\), gdzie \(\displaystyle p,q\) są stałymi lub zmiennymi logicznymi.
Dla niektórych zadań wygodnie jest uzupełnić ten zbiór o dodatkowe operacje, takie jak obliczanie wartości niektórych standardowych funkcji matematycznych (\(\displaystyle \sqrt{\;}, \cos(), \sin(), \exp(), \log(),\) itp.), czy nawet funkcji bardziej skomplikowanych. Na przykład, zastosowanie "szkolnych" wzorów na obliczanie pierwiatków równania kwadratowego byłoby niemożliwe, gdyby pierwiastkowanie było niemożliwe.
Uwaga
Należy pamiętać, że w praktyce funkcje standardowe (o ile są
dopuszczalne) są obliczane przy użyciu czterech podstawowych operacji
arytmetycznych. Dokładniej, jednostka arytmetyczna procesora potrafi wykonywać
jedynie operacje \(\displaystyle +,\,-,\,\times,\,\div\), przy czym dzielenie zajmuje kilka razy
więcej czasu niż pozostałe operacje arytmetyczne. Niektóre procesory (np. Itanium 2) są w stanie wykonywać niejako jednocześnie operację dodawania i mnożenia (tzw. FMADD, fused multiply and add). Praktycznie wszystkie współczesne procesory mają także wbudowany koprocesor matematyczny, realizujący asemblerowe polecenia wyznaczenia wartości standardowych funkcji matematycznych (\(\displaystyle \sqrt{\;}, \cos(), \sin(),\exp(), \log(),\) itp.), jednak wykonanie takiej instrukcji wymaga mniej więcej kilkadziesiąt razy więcej czasu
niż wykonanie operacji dodawania.
Uwaga
Niestety, aby nasz model obliczeniowy wiernie odpowiadał rzeczywistości, musimy w nim uwzględnić fakt, że nawet podstawowe działania arytmentyczne (i, tym bardziej, obliczanie wartości funkcji matematycznych) nie są wykonywane dokładnie. Czasem uwzględnienie tego faktu wiąże się ze znaczącym wzrostem komplikacji analizy algorytmu i dlatego "w pierwszym przybliżeniu" często pomija się to ograniczenie przyjmując model, w którym wszystkie (lub prawie wszystkie) działania arytmetyczne wykonują się dokładnie. Wiedza o tym, kiedy i jak zrobić to tak, by wciąż wyciągać prawidłowe wnioski odnośnie faktycznej realizacji algorytmów w obecności błędów zaokrągleń jest częścią sztuki i wymaga intuicji numerycznej, popartej doświadczeniem.
Mamy trzy podstawowe polecenia złożone: warunkowe, powtarzania i kombinowane.
Warunkowe
if(<math>\displaystyle \cal W</math>)
<math>\displaystyle {\cal A}_1</math>;
else
<math>\displaystyle {\cal A}_2</math>;
gdzie \(\displaystyle {\cal W}\) jest wyrażeniem o wartościach całkowitych (0 odpowiada logicznemu fałszowi, inne wartości --- logicznej prawdzie), a \(\displaystyle {\cal A}_1\) i \(\displaystyle {\cal A}_2\) są poleceniami, przy czym dopuszczamy polecenia puste.
Powtarzane
while(<math>\displaystyle {\cal W}</math>)
<math>\displaystyle {\cal A}</math>;
gdzie \(\displaystyle W\) jest wyrażeniem o wartościach logicznych, a \(\displaystyle \cal A\) jest poleceniem.
Kombinowane
{
<math>\displaystyle {\cal A}_1;\displaystyle {\cal A}_2;\displaystyle \ldots\displaystyle {\cal A}_n;</math>
}
gdzie \(\displaystyle {\cal A}_j\) są poleceniami.
Na podstawie tych trzech poleceń można tworzyć inne, takie
jak pętle for(), czy instrukcje wariantowe switch(), itd.
Mamy też dwa szczególne polecenia, które odpowiadają za "wejście" i "wyjście".
Wprowadzanie danych
<math>\displaystyle {\cal IN}</math>(x,t);
gdzie \(\displaystyle x\) jest zmienną rzeczywistą, a \(\displaystyle t\) "adresem" pewnego funkcjonału \(\displaystyle L:F\toR\) należącym to pewnego zbioru \(\displaystyle T\). W wyniku wykonania tego polecenia w zmiennej \(\displaystyle x\) zostaje umieszczona wartość \(\displaystyle L_t(f)\).
Polecenie to pozwala zdobyć informację o danej \(\displaystyle f\). Jeśli \(\displaystyle F=R^n\) to zwykle mamy \(\displaystyle T=\{1,2,\ldots,n\}\) i \(\displaystyle L_i(f)=f_i\), co w praktyce odpowiada wczytaniu \(\displaystyle i\)-tej współrzędnej wektora danych. W szczególności, ciąg poleceń \(\displaystyle {\cal IN}(x[i],i)\), \(\displaystyle i=1,2,\ldots,n\), pozwala uzyskać pełną informację o \(\displaystyle f\). Jeśli zaś \(\displaystyle F\) jest pewną klasą funkcji \(\displaystyle f:[a,b]\toR\), to możemy mieć np. \(\displaystyle T=[a,b]\) i \(\displaystyle L_t(f)=f(t)\). W tym przypadku, wykonanie polecenia \(\displaystyle {\cal IN}(x,t)\) odpowiada w praktyce skorzystaniu ze specjalnej procedury (albo urządzenia zewnętrznego) obliczającej (mierzącego) wartość funkcji \(\displaystyle f\) w punkcie \(\displaystyle t\).
Wyprowadzanie wyników
<math>\displaystyle {\cal OUT}</math>(<math>\displaystyle {\cal W}</math>);
gdzie \(\displaystyle {\cal W}\) jest wyrażeniem o wartościach rzeczywistych. Polecenie to pozwala "wskazać" kolejną współrzędną wyniku.
Zakładamy, że na początku procesu obliczeniowego wartości wszystkich zmiennych są nieokreślone, oraz że dla dowolnych danych wykonanie programu wymaga wykonania skończonej liczby operacji elementarnych. Wynikiem obliczeń jest skończony ciąg liczb rzeczywistych (albo \(\displaystyle puste\)), którego kolejne współrzędne pokazywane są poleceniem \(\displaystyle {\cal OUT}\).
Środowisko obliczeniowe
Ze względu na swój utylitarny charakter, w metodach numerycznych niemal równie ważna jak dobór optymalnego algorytmu jest jego efektywna implementacja na konkretnej architekturze.
W praktyce mamy dwie możliwości:
- wykorzystanie standardowych języków programowania (C, Fortran, być może ze wstawkami w asemblerze) oraz wyspecjalizowanych bibliotek
- użycie gotowego środowiska obliczeń numerycznych będącego wygodnym interfejsem do specjalizowanych bibliotek numerycznych
Zaleta pierwszego podejścia to (zazwyczaj) szybko działający kod wynikowy, ale kosztem długotrwałego i żmudnego programowania. W drugim przypadku jest na odwrót: deweloperka i testowanie --- wyjątkowo ważne w przypadku programu numerycznego --- postępują bardzo szybko, ale czasem kosztem ogólnej efektywności uzyskanego produktu.
Języki programowania: C i Fortran
Programy numeryczne (a przynajmniej ich jądra obliczeniowe) są zazwyczaj niezbyt wymagające jeśli chodzi o struktury danych, co więcej, prostota struktur danych szybko rewanżuje się efektywniejszym kodem. Dlatego, trawestując Einsteina, w dobrym programie numerycznym należy
używać tak prostych struktur danych, jak to możliwe (ale nie prostszych!...)
Językami opartymi na prostych konstrukcjach programistycznych są: Fortran i C. Dlatego właśnie są to języki dominujące współcześnie pisane programy numeryczne. O ile w przeszłości hegemonia Fortranu była nie do podważenia, o tyle teraz coraz więcej oprogramowania numerycznego powstaje w C.
W naszym wykładzie wybieramy C ze względu na jego uniwersalność, doskonałą przenośność i całkiem dojrzałe kompilatory. Dodajmy, że funkcje w C można mieszać np. z gotowymi bibliotekami napisanymi w Fortranie. Fortran, język o bardzo długiej tradycji, wciąż żywy i mający grono wiernych fanów, jest nadal wybierany przez numeryków na całym świecie między innymi ze względu na jego dopasowanie do zadań obliczeniowych (właśnie w tym celu powstał), a także ze względu na doskonałe kompilatory dostępne na superkomputerach, będące efektem wieloletniej ewolucji i coraz lepszego nie tylko dopasowania kompilatora do spotykanych konstrukcji językowych, ale także na odwrót --- coraz lepszego zrozumienia programistów, jak pisać programy, by wycisnąć jak najwięcej z kompilatora.
Inne popularne języki: Java, Pascal (ten język, zdaje się, jest popularny już
tylko w obrębie wydziału MIM UW...), VisualBasic i inne, nie są zbyt odpowiednie dla
obliczeń numerycznych. Mało tego, np. podstawowy typ numeryczny Pascala:
real nie jest zgodny z powszechnym standardem IEEE 754. Jednak, ze względu na coraz większą
komplikację kodów numerycznych służących np. do prowadzenia zaawansowanych
symulacji metodą elementu skończonego, coraz więcej aplikacji numerycznych wykorzystuje możliwości obiektowych języków C++ i Fortran90.
W przykładach będziemy najczęściej odnosić się do architektury x86, tzn. 32-bitowej IA-32 procesorów firmy Intel i AMD, najczęściej spotykanej w obecnie używanych komputerach. Należy jednak pamiętać, że obecnie następuje przejście na architekturę 64-bitową. Ze względu jednak na brak pewności co do ostatecznie przyjętych standardów w tym obszarze, ograniczymy się do procesorów 32-bitowych. W przykładach będziemy korzystać z kompilatora GCC, który jest omówiony w wykładzie Środowisko programisty.
Prosty program numeryczny w C
Napiszemy teraz program obliczający (w niezbyt wyrafinowany sposób) \(\displaystyle N\)-tą sumę częściową szeregu harmonicznego
Przyjmijmy, że parametr \(\displaystyle N\) będzie miał wartość równą 2006. W pierwszym odruchu, prawie każdy pisze program w rodzaju:
Niepoprawny język.
Musisz wybrać język w następujący sposób: <source lang="html4strict">...</source>
Języki obsługiwane w podświetlaniu składni:
abap, actionscript, actionscript3, ada, apache, applescript, apt_sources, asm, asp, autoit, bash, basic4gl, blitzbasic, bnf, boo, c, c_mac, caddcl, cadlisp, cfdg, cfm, cil, cobol, cpp, cpp-qt, csharp, css, d, delphi, diff, div, dos, dot, eiffel, fortran, freebasic, genero, gettext, glsl, gml, gnuplot, groovy, haskell, html4strict, idl, ini, inno, io, java, java5, javascript, kixtart, klonec, klonecpp, latex, lisp, lotusformulas, lotusscript, lua, m68k, matlab, mirc, mpasm, mxml, mysql, nsis, objc, ocaml, ocaml-brief, oobas, oracle8, pascal, per, perl, php, php-brief, plsql, powershell, python, qbasic, rails, reg, robots, ruby, sas, scala, scheme, sdlbasic, smalltalk, smarty, sql, tcl, text, thinbasic, tsql, vb, vbnet, verilog, vhdl, visualfoxpro, winbatch, xml, xorg_conf, xpp, z80
Sęk w tym, że ten program nie działa! To znaczy: owszem, kompiluje się i uruchamia, ale twierdzi uparcie, że nasza suma wynosi... 1.
Winę za to ponosi linijka
Niepoprawny język.
Musisz wybrać język w następujący sposób: <source lang="html4strict">...</source>
Języki obsługiwane w podświetlaniu składni:
abap, actionscript, actionscript3, ada, apache, applescript, apt_sources, asm, asp, autoit, bash, basic4gl, blitzbasic, bnf, boo, c, c_mac, caddcl, cadlisp, cfdg, cfm, cil, cobol, cpp, cpp-qt, csharp, css, d, delphi, diff, div, dos, dot, eiffel, fortran, freebasic, genero, gettext, glsl, gml, gnuplot, groovy, haskell, html4strict, idl, ini, inno, io, java, java5, javascript, kixtart, klonec, klonecpp, latex, lisp, lotusformulas, lotusscript, lua, m68k, matlab, mirc, mpasm, mxml, mysql, nsis, objc, ocaml, ocaml-brief, oobas, oracle8, pascal, per, perl, php, php-brief, plsql, powershell, python, qbasic, rails, reg, robots, ruby, sas, scala, scheme, sdlbasic, smalltalk, smarty, sql, tcl, text, thinbasic, tsql, vb, vbnet, verilog, vhdl, visualfoxpro, winbatch, xml, xorg_conf, xpp, z80
w której wykonujemy dzielenie 1/i. Obie liczby są typu int i
dlatego, zgodnie z regułami C, wynik ich dzielenia także jest całkowity:
dostajemy część całkowitą z dzielenia tych dwóch liczb, czyli, gdy tylko \(\displaystyle i >
1\), po prostu zero.
Prawidłowy program musi więc wymusić potraktowanie choć jednej z tych liczb jako liczby zmiennoprzecinkowej, co najprościej uzyskać albo przez
Niepoprawny język.
Musisz wybrać język w następujący sposób: <source lang="html4strict">...</source>
Języki obsługiwane w podświetlaniu składni:
abap, actionscript, actionscript3, ada, apache, applescript, apt_sources, asm, asp, autoit, bash, basic4gl, blitzbasic, bnf, boo, c, c_mac, caddcl, cadlisp, cfdg, cfm, cil, cobol, cpp, cpp-qt, csharp, css, d, delphi, diff, div, dos, dot, eiffel, fortran, freebasic, genero, gettext, glsl, gml, gnuplot, groovy, haskell, html4strict, idl, ini, inno, io, java, java5, javascript, kixtart, klonec, klonecpp, latex, lisp, lotusformulas, lotusscript, lua, m68k, matlab, mirc, mpasm, mxml, mysql, nsis, objc, ocaml, ocaml-brief, oobas, oracle8, pascal, per, perl, php, php-brief, plsql, powershell, python, qbasic, rails, reg, robots, ruby, sas, scala, scheme, sdlbasic, smalltalk, smarty, sql, tcl, text, thinbasic, tsql, vb, vbnet, verilog, vhdl, visualfoxpro, winbatch, xml, xorg_conf, xpp, z80
albo bardziej uniwersalnie, rzutując choć jedną z liczb na odpowiedni typ:
Niepoprawny język.
Musisz wybrać język w następujący sposób: <source lang="html4strict">...</source>
Języki obsługiwane w podświetlaniu składni:
abap, actionscript, actionscript3, ada, apache, applescript, apt_sources, asm, asp, autoit, bash, basic4gl, blitzbasic, bnf, boo, c, c_mac, caddcl, cadlisp, cfdg, cfm, cil, cobol, cpp, cpp-qt, csharp, css, d, delphi, diff, div, dos, dot, eiffel, fortran, freebasic, genero, gettext, glsl, gml, gnuplot, groovy, haskell, html4strict, idl, ini, inno, io, java, java5, javascript, kixtart, klonec, klonecpp, latex, lisp, lotusformulas, lotusscript, lua, m68k, matlab, mirc, mpasm, mxml, mysql, nsis, objc, ocaml, ocaml-brief, oobas, oracle8, pascal, per, perl, php, php-brief, plsql, powershell, python, qbasic, rails, reg, robots, ruby, sas, scala, scheme, sdlbasic, smalltalk, smarty, sql, tcl, text, thinbasic, tsql, vb, vbnet, verilog, vhdl, visualfoxpro, winbatch, xml, xorg_conf, xpp, z80
Poprawny kod miałby więc postać
Niepoprawny język.
Musisz wybrać język w następujący sposób: <source lang="html4strict">...</source>
Języki obsługiwane w podświetlaniu składni:
abap, actionscript, actionscript3, ada, apache, applescript, apt_sources, asm, asp, autoit, bash, basic4gl, blitzbasic, bnf, boo, c, c_mac, caddcl, cadlisp, cfdg, cfm, cil, cobol, cpp, cpp-qt, csharp, css, d, delphi, diff, div, dos, dot, eiffel, fortran, freebasic, genero, gettext, glsl, gml, gnuplot, groovy, haskell, html4strict, idl, ini, inno, io, java, java5, javascript, kixtart, klonec, klonecpp, latex, lisp, lotusformulas, lotusscript, lua, m68k, matlab, mirc, mpasm, mxml, mysql, nsis, objc, ocaml, ocaml-brief, oobas, oracle8, pascal, per, perl, php, php-brief, plsql, powershell, python, qbasic, rails, reg, robots, ruby, sas, scala, scheme, sdlbasic, smalltalk, smarty, sql, tcl, text, thinbasic, tsql, vb, vbnet, verilog, vhdl, visualfoxpro, winbatch, xml, xorg_conf, xpp, z80
W tym krótkim przykładzie zetknęliśmy się z największą trudnością pisania programów wykonujących obliczenia numeryczne:
Bardzo łatwo jest napisać jakiś program, który działa i generuje ładnie wyglądające, choć całkowicie fałszywe wyniki.
Pisanie programów numerycznych (podobnie jak innych), wymaga żelaznej dyscypliny i precyzji. Wielokrotne testy, sprawdzające nie tylko kilka konkretnych danych ("czy działa dla \(\displaystyle N=0\)?"), ale także spodziewane jakościowe własności produkowanych rezultatów, są smutną koniecznością w realnym życiu numeryka-programisty.
Typy numeryczne w C
W języku C mamy dostępnych sześć typów numerycznych:
- stałoprzecinkowe, dla reprezentacji liczb całkowitych
-
intorazlong int. W realizacji GCC na komputery x86, oba typy:intilong intsą identyczne (32-bitowe) i ich zakres wynosi około \(\displaystyle -2.1\cdot 10^9\ldots +2.1\cdot 10^9\). Typinti jemu pokrewne odnoszą się do liczb całkowitych ze znakiem (dodatnich lub ujemnych). Ich warianty bez znaku:unsigned int, itp. odnoszą się do liczb bez znaku (nieujemnych), dlatego np. zakresemunsigned intbędzie w przybliżeniu \(\displaystyle 0\ldots +4.2\cdot 10^9\). -
long long int(64-bitowy) o zakresie w przybliżeniu \(\displaystyle -9.2\cdot 10^{18}\ldots +9.2\cdot 10^{18}\).
-
- zmiennoprzecinkowe, dla reprezentacji liczb rzeczywistych
-
float, pojedynczej precyzji, 32-bitowy, gwarantuje precyzję około \(\displaystyle 10^{-7}\) i zakres liczb reprezentowalnych w przybliżeniu \(\displaystyle 10^{-38}\ldots 10^{38}\); -
double, podwójnej precyzji, 64-bitowy, ma precyzję na poziomie \(\displaystyle 10^{-16}\) przy orientacyjnym zakresie \(\displaystyle 10^{-308}\ldots 10^{308}\); -
long double, rozszerzonej podwójnej precyzji, 80-bitowy, o precyzji rzędu \(\displaystyle 10^{-20}\) i odpowiadający standardowi double extended IEEE 754.
-
Powyższe typy zmiennoprzecinkowe w realizacji na PC odpowiadają
standardowi IEEE 754, o którym będzie mowa w wykładzie o arytmetyce zmiennoprzecinkowej. Standardowo, operacje arytmetyczne na obu typach float i double są tak samo pracochłonne, gdyż wszystkie obliczenia w C wykonywane są z maksymalną dostępną precyzją (czyli, na procesorach architektury IA-32 Intela i AMD: w precyzji oferowanej przez typ long double), a następnie dopiero wynik zapisywany do zmiennej rzutowany jest na stosowny typ.
Mimo to, czasem można skorzystać z typu pojedynczej precyzji float, który oferuje znacznie większe możliwości optymalizacji uzyskanego kodu. Ponadto, obiekty typu float zajmują dwukrotnie mniej miejsca w pamięci niż double, dając możliwość lepszego wykorzystania pamięci podręcznej (cache) i przetwarzania wektorowego.
Stałe matematyczne i podstawowa biblioteka matematyczna
Język C jest językiem "małym" i, jak wiadomo, nawet proste operacje
wejścia-wyjścia są w istocie nie częścią języka, ale funkcjami
bibliotecznymi lub makrami. Z drugiej strony jednak, jak zorientowaliśmy się, nie stwarza to programiście żadnych specjalnych niedogodności. Podobnie rzecz ma się z funkcjami matematycznymi. Podstawowe funkcje matematyczne (\(\displaystyle \sin, \cos, \exp, \ldots\), itp.) nie są składnikami języka C, lecz w zamian są zaimplementowane w tzw. standardowej bibliotece matematycznej libm.a; prototypy tych funkcji oraz definicje rozmaitych stałych matematycznych: \(\displaystyle \pi, e, \ldots\) itp.
znajdują się w pliku nagłówkowym math.h. Aby więc skorzystać z tych
funkcji w programie, należy
- w nagłówku pliku, w którym korzystamy z funkcji lub stałych matematycznych, umieścić linię
#include <math.h> - przy linkowaniu dołączyć bibliotekę matematyczną za pomocą opcji
-lm
Przykład
Oto prosty program numeryczny w C; drukuje on tablicę wartości sinusów losowo wybranych liczb z przedziału \(\displaystyle [0,2\pi]\).
Niepoprawny język.
Musisz wybrać język w następujący sposób: <source lang="html4strict">...</source>
Języki obsługiwane w podświetlaniu składni:
abap, actionscript, actionscript3, ada, apache, applescript, apt_sources, asm, asp, autoit, bash, basic4gl, blitzbasic, bnf, boo, c, c_mac, caddcl, cadlisp, cfdg, cfm, cil, cobol, cpp, cpp-qt, csharp, css, d, delphi, diff, div, dos, dot, eiffel, fortran, freebasic, genero, gettext, glsl, gml, gnuplot, groovy, haskell, html4strict, idl, ini, inno, io, java, java5, javascript, kixtart, klonec, klonecpp, latex, lisp, lotusformulas, lotusscript, lua, m68k, matlab, mirc, mpasm, mxml, mysql, nsis, objc, ocaml, ocaml-brief, oobas, oracle8, pascal, per, perl, php, php-brief, plsql, powershell, python, qbasic, rails, reg, robots, ruby, sas, scala, scheme, sdlbasic, smalltalk, smarty, sql, tcl, text, thinbasic, tsql, vb, vbnet, verilog, vhdl, visualfoxpro, winbatch, xml, xorg_conf, xpp, z80
Zwróćmy uwagę na linię x = rand()/(double)RAND_MAX; Funkcja rand()
zwraca losową liczbę całkowitą z przedziału [0,RAND_MAX], więc iloraz z
predefiniowaną stałą RAND_MAX będzie liczbą z przedziału \(\displaystyle [0,1]\). Dla
prawidłowego uzyskania losowej liczby z przedziału \(\displaystyle [0,1]\) kluczowe jest jednak
zrzutowanie jednej z dzielonych liczb na typ double! Gdyby tego nie zrobić,
uzyskalibyśmy zawsze \(\displaystyle x=0\) lub sporadycznie \(\displaystyle x=1\), zgodnie z regułą C: "typ
wyniku jest zgodny z typem argumentów".
Kompilujemy ten program, zgodnie z uwagami uczynionymi na początku, poleceniem
Środowisko obliczeń numerycznych: MATLAB i jego klony
Inną możliwością prowadzenia obliczeń numerycznych jest skorzystanie z gotowych, wyspecjalizowanych środowisk programistycznych, dających użytkownikowi m.in. wygodny interfejs do bardziej skomplikowanych bibliotek numerycznych.
W końcu lat siedemdziesiątych ubiegłego wieku, Cleve Moler wpadł na pomysł stworzenia prostego interfejsu do ówcześnie istniejących bibliotek numerycznych algebry liniowej: pakietów LINPACK i EISPACK
(których był współautorem). Stworzone przez niego: język skryptów i łatwe w użyciu narzędzia manipulacji macierzami, zdobyły wielką popularność w środowisku naukowym. W 1984 roku Moler skomercjalizował swe dzieło pod nazwą MATLAB (od: "MATrix LABoratory").
{kind=link}
MATLAB wkrótce rozrósł się potężnie, implementując (lub wykorzystując) wiele najlepszych z istniejących algorytmów numerycznych, a także oferując bogate możliwości wizualizacji wyników. Dzięki swemu interfejsowi, składającemu się z prostych, niemal intuicyjnych funkcji, oraz ogromnym możliwościom jest jednym z powszechniej używanych pakietów do prowadzenia symulacji komputerowych w naukach przyrodniczych (i nie tylko).
Interpreter MATLABa jest dosyć wolny, dlatego podstawową regułą pisania efektywnych kodów w MATLABie jest maksymalne wykorzystanie gotowych (prekompilowanych) funkcji MATLABa oraz --- zredukowanie do minimum obecności takich struktur programistycznych jak pętle.
Kierując się podobnymi przesłankami co Moler, oraz bazując na wielkim sukcesie MATLABa, John W. Eaton z Wydziału Inżynierii Chemicznej Uniwersytetu Wisconsin w USA, zaczął w 1994 roku opracowywać darmowe (udostępniane na tzw. licencji GPL) oprogramowanie o funkcjonalności maksymalnie zbliżonej do MATLABa: Octave. Wersja 1.0 pakietu Octave ukazała się w 1996 roku i jest intensywnie rozwijana do dziś.
{kind=link}
Drugim udanym klonem MATLABa jest francuski Scilab, opracowany w laboratoriach INRIA i wciąż doskonalony. W subiektywnej ocenie autorów niniejszych notatek, nie dorównuje on elegancji i szlachetnej prostocie Octave. Na plus tego pakietu należy zaliczyć m.in. znacznie bardziej rozbudowany zestaw funkcji podstawowych, na minus --- przede wszystkim znacznie mniejszy stopień zgodności z MATLABem, a poza tym niewygodny system pomocy oraz "toporną" (choć o dużym potencjale) grafikę.
{kind=link}
Korzystając z dowolnego z omówionych powyżej pakietów, otrzymujemy:
- możliwość obliczania funkcji matematycznych (nawet dość egzotycznych), finansowych, analizy sygnałów, itp.;
- bardzo szeroki zakres nowoczesnych narzędzi umożliwiających wykonywanie podstawowych zadań numerycznych, takich jak: rozwiązywanie równań, obliczanie całek, itd.;
- efektowną wizualizację wyników w postaci wykresów dwu- i trójwymiarowych, a także funkcje do manipulacji obrazem i dźwiękiem;
- możliwość nieograniczonych rozszerzeń przy użyciu funkcji i skryptów tworzonych przez osoby trzecie (lub własnych).
Jeśli uwzględnić dodatki wielce ułatwiające życie, w tym rozbudowane funkcje wejścia-wyjścia, to narzędzie robi się rzeczywiście intrygujące, jako środowisko obliczeń numerycznych "dla każdego" (nie tylko dla profesjonalnego numeryka). Stąd wielka popularność MATLABa w środowiskach inżynierskich, gdyż umożliwia szybką implementację rozmaitych --- zwłaszcza testowych --- wersji algorytmu, np. przeprowadzania skomplikowanej symulacji. Po zweryfikowaniu wyników można ewentualnie rozpocząć implementację w docelowym środowisku (np. na masywnie równoległym komputerze, w Fortranie 95, z wykorzystaniem komercyjnych bibliotek i specyficznymi optymalizacjami kodu), choć bardzo często wyniki uzyskane w MATLABie w zupełności wystarczą.
Zarówno MATLAB, jak Octave i Scilab, opierają się w dużym zakresie na darmowych --- acz profesjonalnych --- zewnętrznych bibliotekach numerycznych (BLAS, LAPACK, FFTW, itp.)
MATLAB jest wciąż niedościgniony jeśli chodzi o narzędzia programistyczne (np. ma wbudowany --- działający na bieżąco w czasie edycji kodu źródłowego! --- debugger, a także kompilator funkcji JIT) oraz możliwości wizualizacji danych i wyników obliczeń. Jeśli zaniedbać koszt zakupu dodatkowych modułów, ma także najbogatszy zestaw funkcji numerycznych. W chwili pisania niniejszego tekstu, (stosunkowo tanie) wersje studenckie MATLABa, nie są oferowane w Polsce przez producenta, choć z drugiej strony instalacje MATLABa są często dostępne (nawet w wersji profesjonalnej) w komputerowych laboratoriach akademickich w Polsce.
Zarówno w MATLABie, jak i w Octave, jest możliwe pisanie funkcji, które będą prekompilowane, dając tym samym znaczące przyspieszenie działania. Najnowsze wersje MATLABa (od wersji 6.5) wykorzystują zresztą domyślnie kompilację JIT --- w trakcie pisania kodu źródłowego funkcji.
Wybór pomiędzy darmowymi klonami MATLABa: Octave i Scilabem, jest właściwie kwestią osobistych preferencji. W ninijeszym kursie będziemy posługiwać się Octave. Dzięki temu, będziemy mogli m.in. sprawnie wykonywać różne eksperymenty numeryczne, skupiając się na ich treści, a nie głównie na stronie implementacyjnej (która może być bardzo czasochłonna).
Octave jest dołączany do większości popularnych dystrybucji Linuxa, najczęściej jednak użytkownik musi samodzielnie doinstalować go z płytki instalacyjnej. Ponadto, kody źródłowe najświeższej wersji Octave są dostępne na stronie http://www.octave.org. Dodatkowo, pod http://octave.sourceforge.net znajdziemy pakiet rozszerzeń do Octave, pod nazwą Octave-forge. Wymaga on od użytkowników Linuxa samodzielnej (przebiegającej bezproblemowo) instalacji. Octave można także zainstalować pod Windows, korzystając z programu instalacyjnego dostępnego pod adresem internetowym http://octave.sourceforge.net: w Windowsowej wersji Octave, pakiet Octave-forge jest standardowo dołączony.
Pierwsze kroki w Octave
Octave uruchamiamy poleceniem octave,
Naturalnie, Octave zachowuje wszystkie możliwości kalkulatora naukowego, wykonując podstawowe operacje arytmetyczne i obliczając wartości wielu funkcji matematycznych; oto zapis takiej sesji Octave:
Ostatnie dwa wyniki dają nam namacalny dowód, że obliczenia wykonywane są
numerycznie, ze skończoną precyzją: w Octave niektóre tożsamości matematyczne
są spełnione jedynie w przybliżeniu, np. \(\displaystyle \sin(\pi) \approx 0\) oraz
\(\displaystyle e^{i\pi} \approx -1\). Przy okazji widzimy, że Octave dysponuje podstawowymi
stałymi matematycznymi (oczywiście, są to także wartości przybliżone!):
e , 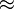 2.71828182845905
2.71828182845905pi
oraz jednostką urojoną 3.14159265358979i \(\displaystyle = \sqrt{-1}\).
Octave ma dobrą dokumentację, dostępną w trakcie sesji
Octave; dla każdej funkcji, stałej itp. można uzyskać jej dobry opis przy
użyciu polecenia help.
Podstawowym obiektem, z jakim mamy do czynienia w Octave, jest macierz dwuwymiarowa \(\displaystyle n\times m\), o elementach rzeczywistych lub zespolonych,
W szczególności, biorąc \(\displaystyle m=1\) albo \(\displaystyle n=1\), dostajemy wektor (kolumnowy lub wierszowy
Z kolei dla \(\displaystyle m=n=1\) mamy do czynienia ze "zwykłymi" liczbami rzeczywistymi lub zespolonymi.
Octave umożliwia, za swoim pierwowzorem --- MATLABem, bardzo wygodną pracę z macierzami.
Wprowadzanie macierzy do Octave jest bardzo intuicyjne i możemy zrobić to na kilka sposobów, w zależności od potrzeb. Można robić to interakcyjnie, podając elementy macierzy z linii komend, na przykład:
definiuje macierz kwadratową \(\displaystyle 3\times 3\) o elementach równych
Tak więc, macierz w Octave definiujemy przez podanie jej elementów. Elementy wprowadzamy kolejno wierszami, elementy w wierszu oddzielamy spacjami (lub ewentualnie przecinkami), natomiast kolejne wiersze oddzielamy średnikami.
Macierz możemy także tworzyć stopniowo, wprowadzając jeden za drugim jej kolejne elementy:
Pierwsza komenda określa B jako macierz \(\displaystyle 1\times 1\), czyli zwykłą
liczbę, druga -- rozszerza nasz obiekt do wektora, natomiast trzecia --
powoduje, że B zostaje rozszerzony do macierzy \(\displaystyle 3\times 2\). Zauważmy, że
elementom B o nieokreślonych przez nas wartościach zostaje przypisana domyślna
wartość zero.
Jeśli nie chcemy za każdym razem obserwować echa prowadzonych przez nas działań
na macierzy B, komendy powinniśmy kończyć średnikiem. Tak więc, znacznie
wygodniej będzie nam napisać
B = zeros(3,2); B(1,1) = 3 + B(1,1); B(2,1) = pi; B(3,2) = 28; B
Ostatnie polecenie -- B bez średnika na końcu -- spowoduje
wypisanie zawartości B na ekran.
Tak utworzoną macierz możemy zapisać do pliku, wykorzystując jeden z kilku formatów:
- tekstowy
- binarny
- HDF5
Zapis w formacie tekstowym to po prostu zapis do formatu ASCII. Ze względu na późniejszą konwersję z zapisu w postaci dziesiętnej do dwójkowej, wiąże się z drobnymi niedokładnościami w odczycie.
save macierzb.dat B
W wyniku dostajemy
Zapis binarny to prostu zrzut stanu pamięci
save -binary macierzb.dat B
Format HDF5 to format gwarantujący pełną przenośność danych pomiędzy różnymi architekturami, akceptowany przez wiele zewnętrznych aplikacji, m.in. OpenDX.
save -hdf5 macierzb.dat B
Dane z pliku wczytujemy z powrotem poleceniem
load macierzb.dat
Sesję Octave kończymy poleceniem quit.
Notacja dwukropkowa Molera
Do istniejącej macierzy możemy odwoływać się tradycyjnie, czyli do pojedynczych
elementów, np. alfa = D(2,2), lub do jej większych bloków, używając popularnej tzw. notacji dwukropkowej Molera.
{kind=link}
D przy użyciu notacji dwukropkowejJest ona
szalenie intuicyjna, a mianowicie: pisząc na przykład v = D(2:5,2)
definiujemy (wektor) \(\displaystyle v\), który zawiera wiersze macierzy \(\displaystyle D\) od 2 do 5 wybrane z
drugiej kolumny. Podobnie, pisząc W = D(2:3,5:7) definiujemy macierz
\(\displaystyle W\) wymiaru
\(\displaystyle 2\times 3\), o elementach, które zostały wybrane z przecięcia wierszy od 2 do 3 z
kolumnami od 5 do 7 macierzy \(\displaystyle D\).
{kind=link}
DDodatkowo, aby odwołać się do całego 4. wiersza (odpowiednio: 5. kolumny)
macierzy \(\displaystyle D\), można użyć skrótowej notacji D(4,:) (odpowiednio:
D(:,5)).
Odwołanie się do całej macierzy jest także możliwe (przez użycie jej nazwy, np.
A = 2*D lub G = log(abs(D))).
Notację dwukropkową można także wykorzystać do wygenerowania samodzielnych zbiorów indeksów:
i dlatego pętle, które w C zapisywalibyśmy
for(i=0; i<=N; i++)
{
...instrukcje...
}
for(i=N; i>=1; i--)
{
...instrukcje...
}
w Octave zapiszemy
for i=0:N ...instrukcje... end for i=N:-1:1 ...instrukcje... end
Za chwilę przekonamy się, jak można w ogóle pozbyć się potrzeby stosowania większości pętli w kodach Octave i MATLABa.
Wektoryzacja w Octave
Ponieważ podstawowymi obiektami w Octave są wektory i macierze, predefiniowane operacje matematyczne wykonują się od razu na całej macierzy. Bez żadnej przesady możena stwierdzić, że umiejętność wektoryzacji i blokowania algorytmów jest podstawą pisania efektywnych implementacji algorytmów w Octave.
Zobaczmy kilka prostych przykładów zawartych w tabeli poniżej. W pierwszej kolumnie tabeli, dane zadanie zaimplementujemy w Octave przy użyciu pętli (zwróćmy przy okazji uwagę na to, jak programuje się pętle w Octave, one nie są zupełnie bezużyteczne...). W drugiej kolumnie zobaczymy, jak to samo zadanie można wykonać korzystając z operatorów lub funkcji macierzowych.
| Tradycyjny kod w Octave, używający pętli | Efektywny kod wektorowy (macierzowy) w Octave | |
| Alg 1 | s = 0; for i = 1:size(x,1) s = s + abs(x(i)); end | s = sum(abs(x)); |
| Alg 2 | N = 500; h = (b-a)/(N-1); for i = 1:N x(i) = a + (i-1)*h; y(i) = sin(x(i)); end plot(x,y); | N = 500; x = linspace(a,b,N); y = sin(x); plot(x,y); |
| Alg 3a | for i = 1:size(C,1), for j = 1:size(C,2), for k = 1:size(A,2), C(i,j) = C(i,j) + A(i,k)*B(k,j); end end end | C = C + A*B; |
| Alg 3b | for i = 1:size(C,1), for j = 1:size(C,2), C(i,j) = C(i,j) + A(i,:)*B(:,j); end end | C = C + A*B; |
Zwróćmy uwagę na to, że kod wektorowy Octave oraz, w jeszcze większym stopniu, kod macierzowy jest znacznie bardziej elegancki i czytelniejszy od tradycyjnego. Widać to dobrze na wszystkich powyższych przykładach.
Pierwszy przykład pokazuje też, że kod macierzowy jest elastyczniejszy: albowiem
obliczy sumę modułów wszystkich elementów x nie tylko gdy x
jest wektorem (co musieliśmy milcząco założyć w kodzie w lewej kolumnie), ale
tak samo dobrze zadziała, gdy x jest macierzą!
Szczególnie wiele na czytelności i wygodzie zyskujemy w drugim przykładzie,
gdzie najpierw funkcja linspace pozwala nam uniknąć żmudnego
wyznaczania \(\displaystyle N\) równoodległych węzłów \(\displaystyle x_i\) w odcinku \(\displaystyle [a,b]\), a następnie
funkcja sin zaaplikowana do całego wektora \(\displaystyle x\) daje wartość sinusa w
zadanych przez nas węzłach.
Kod wektorowy lub (zwłaszcza) kod macierzowy jest też znacznie szybszy. Spójrzmy
teraz na przykłady: (3a) i (3b), które pokażą nam prawdziwą moc funkcji
macierzowych, unikających wielokrotnie zagnieżdżonych pętli. Oba dotyczą
operacji mnożenia dwóch macierzy. Przykład (3a) w wersji z potrójną pętlą
for naśladuje sposób programowania znany nam z C lub Pascala,
natomiast przykład (3b) zdaje się być napisany odrobinę w duchu wektorowym
(brak trzeciej, wewnętrznej pętli, zastąpionej operacją wektorową: iloczynem
skalarnym \(\displaystyle i\)-tego wiersza \(\displaystyle A\) i \(\displaystyle j\)-tej kolumny \(\displaystyle B\)). Poniżej porównanie
czasów działania tych trzech implementacji w przypadku macierzy \(\displaystyle 64\times 64\)
(czasy dla PC z procesorem Celeron 1GHz):
- Dla pętli postaci
C(i,j)=C(i,j)+A(i,k)*B(k,j)uzyskano czas 21.6s, - Dla pętli postaci
C(i,j)=C(i,j)+A(i,:)*B(:,j)--- 0.371s - Dla pętli postaci
C=C+A*Bkod działał jedynie 0.00288s!
Widzimy, jak beznadziejnie wolny jest kod oparty na trzech zagnieżdżonych
pętlach: jest on kilka tysięcy razy wolniejszy od implementacji macierzowej
C = C + A*B. Po wektoryzacji wewnętrznej pętli, program doznaje
kilkudziesięciokrotnego przyspieszenia, lecz nadal jest ponadstukrotnie
wolniejszy od kodu macierzowego!
Literatura
Materiały zgromadzone w kolejnych wykładach są przewodnikiem po omawianych w nich zagadnieniach. Prawdziwe studia wymagają wszelako studiowania --- także dobrej literatury fachowej! Dlatego pod koniec każdego wykładu umieszczamy informację o tym, gdzie szukać pogłębionych informacji na temat wykładanego materiału.
Naszym podstawowym źródłem będzie nowoczesny podręcznik
- D. Kincaid, W. Cheney, Analiza numeryczna, Wydawnictwa Naukowo-Techniczne, Warszawa, 2006.
Oprócz niego, w języku polskim było wydanych kilka innych podręczników i monografii (niestety, większość z nich dość dawno temu)
- A. Bjorck, G. Dahlquist, Metody numeryczne, Państwowe Wydawnictwo Naukowe, Warszawa, 1987,
- M. Dryja, J. i M. Jankowscy, Przegląd metod i algorytmów numerycznych, Wydawnictwa Naukowo-Techniczne, Warszawa, 1988,
- Z. Fortuna, B. Macukow, J. Wąsowski, Metody numeryczne, Wydawnictwa Naukowo-Techniczne, Warszawa, 1982, 2005.
- A. Kiełbasiński, H. Schwetlick, Numeryczna algebra liniowa, Wydawnictwa Naukowo-Techniczne, Warszawa, 1992.
- A. Ralston, Wstęp do analizy numerycznej, Państwowe Wydawnictwo Naukowe, Warszawa, 1983,
- J. Stoer, R. Bulirsch, Wstęp do analizy numerycznej, Państwowe Wydawnictwo Naukowe, Warszawa, 1987.
Do tego warto wspomnieć o kilku wartościowych podręcznikach i monografiach w języku angielskim
- K. Atkinson, An Introduction to Numerical Analysis, Wiley, 1989,
- K. Atkinson, Elementary Numerical Analysis, Wiley, 2004,
- P. Deuflhard, A. Hohmann, Numerical Analysis in Modern Scientific Computing. An Introduction, Springer, 2003,
- A. Quarteroni, R. Sacco, F. Saleri, Numerical Mathematics, Springer, 2000,
- E. Suli, D. Mayers, An Introduction to Numerical Analysis, Cambridge University Press, 2006.
Zachęcamy gorąco do zapoznania się z nimi i sztuką obliczeń numerycznych, gdyż jej prawdziwy urok, niuanse i tajemnice --- podobnie jak w przypadku każdej innej sztuki --- może docenić jedynie wyrobiony odbiorca.
Jeśli chodzi o programowanie w Octave lub w MATLABie, warto skorzystać z internetowego podręcznika Octave lub krótkiego omówienia możliwości MATLABa zawartego w skrypcie MATLAB Primer (prawie wszystko bezpośrednio przenosi się do Octave'a).