Z Skrypty dla studentów Ekonofizyki UPGOW
Spis treści |
Generacja liczb losowych: liczby o rozkładzie jednostajnym
Liniowy generator kongruencyjny
Generator liczb pseudolosowych to procedura, generująca deterministycznie ciąg bitów, który pod pewnymi względami jest nieodróżnialny od ciągu uzyskanego z prawdziwie losowego źródła.
Najprostszym przykładem jest liniowy generator kongruencyjny (ang. Linear congruential generator, LCG), który jest wyznaczony przez relację rekurencyjną:
- \(X_{n+1} = \left( a X_n + c \right)~~\bmod~~m\)
Jego implementacja w octave:
function y=myran(x); a=1664525; b=1013904223; m=2^32; y=mod(a*x+b,m); return; end
przykład jego użycia do generacji pseudolosowych liczb z przedziału (0,1):
x(1)=123; for i=2:10; x(i)=myran(x(i-1)); disp(x(i)/2^32); end
Generator ten ma wiele mankamentów:
- okres niskich bitów jest o wiele niższy od okresu całego generatora.
x(1)=1234; for bitn=1:10 for i=2:30; x(i)=myran(x(i-1)); printf("Bit %d: %d\n", bitn,bitget(x(i),bitn) ); end a=input('cont?','s'); if (a=='q') break; end end
- Jeżeli użyjemy LCG do generacji punktów w n-wymiarowej przestrzeni to punkty te będą leżały na \(m^{1/n}\) hiperpowierzchniach. W przypadku idealnego generatora jednostajnego, rozkład punktów jest izotropowy i nie powinien zawierać żadnych regularności.
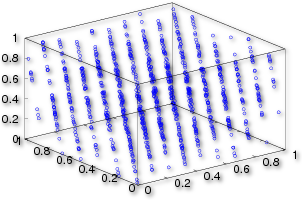 Hiperpłaszczyzny w przestrzeni trzech kolejnych wywołań generatora LCG
Hiperpłaszczyzny w przestrzeni trzech kolejnych wywołań generatora LCG

function y=myranbad(x); a=65539; b=0; m=2^31; y=mod(a*x+b,m); return; end
x(1)=1234; for i=2:3000; x(i)=myranbad(x(i-1)); end X=reshape(x,[3,length(x)/3]); randmax=2^31*1.0 plot3(X(1,:)/randmax, X(2,:)/randmax, X(3,:)/randmax, '*')
Współczesne generatory wysokiej jakości: Mersenne Twister
Jednym z lepszych generatorów używanym obecnie jest Mersenne Twister. Jest on szybki i zapewnia dobre własności statystyczne generowanego ciągu liczb. Jego wadą jest stosunkowo duża liczba instrukcji z których się składa, co ma znaczenie w przypadku jego implementacji na architekturach wbudowanych a nie odgrywa większej roli na klasycznych komputerach PC. W systemie GNU Octave funkcja rand używa właśnie generatora Mersenne Twister.

Poniższy kod przedstawia graficznie kolejne trzy liczby wylosowane za pomocą generatora Mersenne Twister. Wykres trzech kolejnych wygenerowanych liczb wygląda bardziej jednorodnie od poprzedniego.
x=rand(1,3000); X=reshape(x,[3,length(x)/3]); plot3(X(1,:), X(2,:), X(3,:), 'o')
Liczby o zadanym rozkładzie
Dysponując generatorem liczb pseudolosowych o rozkładzie jednostajnym z wartościami w (0,1) możemy otrzymać generator o dowolnym rozkładzie dokonując z transformacji gęstości prawdopodobieństwa. Jeśli \(u\) jest zmienną o rozkładzie jednostajmym o docelowy rozkład ma dystrybuantę \(F_{\xi}(x)=\int_{-\infty}^x f(x)\) to zmienna y: \(y=F_{\xi}^{-1}(u)\) będzie miała rozkład \(\displaystyle f(y)\). Metodę tą można wykorzystać do otrzymania generatora o rozkładzie eksponencjalnym \(e^{-x}\) dysponując rozkładem jednostajnym. W takim przypadku dystrybuanta jest również funkcją \(F(x)=e^{-x}\) i jej funkcja odwrotną jest \(F^{-1}(x)=-log(x)\). Możemy to sprawdzić wykonując eksperyment numeryczny polegający na wysymulowaniu dużej liczby próbek z generatora jednostajnego i następnie zrobieniu histogramu tych wielkości.
N=10000; X=rand(1,N); X=-log(X); hold off; h=0.1 xmax=16 hist(X,[-1:h:xmax],1/h) hold on; fplot(@(x) exppdf(x,1),[1e-3,xmax],'r')
- w linii
X=rand(1,N);
jest generowane N liczb z rozkładem jednostajnym (wykorzystującym wbudowany w system generator liczb losowych, w przypadku GNU/Octave jest do Mersenne Twister).
- linia:
hist(X,[-1:h:xmax],1/h)
generuje histogram z danych w tabeli X. Proszę zauważyć, że drugi argument jest normą tego histogramu, która zgodnie z dokumentacja (help hist) jest sumą wartości wszystkich słupków. Ponieważ chcemy porównać ten histogram z gęstością to mamy:
\(1=\int_0^\infty f(x) dx=\sum_{i=1}^N f(x_i) h\)
z czego nam wynika, że suma wysokości słupków gęstości unormowanej do jedynki wynosi:
\(\sum_{i=1}^N f(x_i) =1/h\)
- w linii
fplot(@(x) exppdf(x,1),[1e-3,xmax],'r')
wykres rysujemy od 0.001(1e-3) zamiast 0.0. Jest to spowodowane tym, że funkcja exppdf nie jest ciągła w zerze i procedura rysująca fplot będzie usiłowała niepotrzebnie zagęścić punkty wykresu w nieciągłości w przypadku wpisania 0.0 w dolny zakres.
Transformacja zmiennej losowej
Załóżmy, że jest dana zmienna losowa \(\mathbf x\) a funkcja \(g(x)\) jest funkcją zmiennej rzeczywistej. Wyrażenie
\(\mathbf y=g(\mathbf x)\)
definiuje w następujący sposób nową zmienną losową \(\mathbf y\): dla danego zdarzenia \(\xi\) zmienna losowa jest liczbą \(\mathbf x(\xi)\) więc \(g(\mathbf x(\xi))\) jest również liczbą.
Dystrybuanta zmiennej \(\mathbf y\) jest określona przez:
\(F_y(y)=P\{\mathbf y \le y\}=P\{g(x) \le y\}\)
Wynika z tego, że aby wyrazić dystrybuantę \(F_y(y)\) poprzez dystrybuantę \(F_x(x)\), musimy znaleźć zbór na osi x taki dla którego \(g(\mathbf x) \le y\) i obliczyć prawdopodobieństwo znalezienia wartości zmiennej \(\mathbf x\) w tym zbiorze.
Przykład: kwadrat zmiennej losowej \(\mathbf y=x^2\)
Jeśli \(y \ge 0\) to \( g(x)=x^2 \le y\) dla \(-\sqrt y \le x\le \sqrt y\) Dlatego mamy dla \(y \ge 0\):
\(F_y(y)=P\{-\sqrt y \le x \le \sqrt y \} = F_x(\sqrt y) -F_x(-\sqrt y) \)
natomiast dla \(y < 0 \)
\(F_y(y)=0\).

x=rand(1,10000)*2-1; h=0.01 hist(x.^2,[0:h:1],1/h) hold on fplot(@(xx) 1./(2*sqrt(xx)),[0.005,1] ,'r*') hold off
Dla ilustracji przyjmijmy, że zmienną \(\mathbf x\) ma rozkład jednostajny na odcinku \((-1,1)\). Dystrybuantą takiego rozkładu jest funkcja
\(F_x(x)=\frac{1}{2}+\frac{x}{2}\), dla \(|x|<1\).
tak więc dystrybuantą zmiennej losowej \(\mathbf y\) będzie:
\(F_y(y)=\frac{1}{2}+\frac{\sqrt(y)}{2}-(\frac{1}{2}-\frac{\sqrt(y)}{2}=\sqrt y\),
której odpowiada funkcja gęstości \(f_y(y)=\frac{1}{2 \sqrt y}\). Poniższy program jest symulacją tego przypadku. Generujemy 10000 zmiennych z przedziału -1 do 1, a rysujemy ich histogram i porównujemy z gęstością \(f_y(y)\).
Przypadki ogólne
Aby znaleźć gęstość rozkładu \(f_y(y)\) dla pewnego \(y\), rozwiązujemy równanie \(y=g(x)\). Oznaczmy rzeczywiste pierwiastki tego równania przez \(x_n\). Wtedy mamy:
\[f_y(y)=\frac{f_x(x_1)}{|g'(x_1)|}+...+ \frac{f_x(x_n)}{|g'(x_n)|}\]
gdzie \(g'(x)\) oznacza pochodną \(g(x)\).
Przypuścmy teraz, ze chcemy uogólnić to twierdzenie na przypadek wielowymiarowy. Załóżmy, że mamy zmienne losowe \(x_1,...,x_n\) oraz \(y_1,...,y_n\) tak, że każda zmienna \(y_i\) jest pewną odwracalną funkcją zmiennych \(x_1,...,x_n\). W takim przypadku w punktcie \(x_1,...,x_n\) istnieje Jakobian przekształcenia odwrotnego i zachodzi:
\[p(y_1,...,y_n) = |\frac{\partial(x_1,\ldots, x_n)}{\partial(y_1,\ldots, y_n)}| p(x_1,...,x_n)\].
Rozkład Gaussa
Ważnym rozkładem, który niezwykle często się pojawia w różnego rodzaju symulacjach numerycznych jest rozkład Gaussa. Można go otrzymać z rozkładu jednostajnego za stodując metodę transformacji zmiennej losowej. Wymaga to znajomości odwrotnej funkcji błędu Gaussa
N=10000 X=rand(1,N); X=sqrt(2)*erfinv(2.*X-1); hold off; h=0.1 xmax=5 hist(X,[-xmax:h:xmax],1/h) # drugi argument to norma histogramu hold on; fplot(@(x) normpdf(x,0,1),[-xmax,xmax],'r-*') hold off
Użycie odwrotnej funkcji błędu Gaussa, o ile jest całkowicie poprawne matematycznie, to nie jest najlepszym rozwiązaniem z punktu widzenia efektywnej implementacji na komputerze. Najlepszą metodą jest zastosowanie tych funkcji, które są niskopoziomowo zaimplementowane w jednostkach CPU (np. w . Takimi funkcjami są funkcje trygonometryczne, eksponenta lub pierwiastek.
Rozkład Gaussa można także otrzymać stosując Centralne Twierdzenie Graniczne. Taka metoda nie ma większego znaczenia praktycznego, jednak jest to ciekawy eksperyment numeryczny. Poniższy kod generuje N liczb o rozkładzie zbliżonym do Gaussowskiego z n rozkładów jednostajnych. Proszę uruchomić ten kod dla n=1,2,3 i 4 i porównać wyniki. Okazuje się, że nawet dla małych n rozkład będący znormalizowaną sumą przypomina wizualnie rozkład Gaussa. Należy jednak pamiętać, że pomimo dużego podobieństwa, bląd jest duży dla większych wartości x (tzw. ogonów). Skończona suma rozkładów jednostajnych ma zawsze skończony nośnik, w przeciwieństwie to rozkładu Gaussa, który ma nośnik na całej osi rzeczywistej.
N=10000 n=3; for i=1:N; gclt(i)=(sum(rand(1,n))-n*0.5)/(0.3*sqrt(n)); end; hold off; hist(gclt,[-5:0.1:5],10) hold off; hist(gclt,[-5:0.1:5],10) hold on; fplot(@(x) normpdf(x),[-5,5])
Algorytm Boxa-Mullera
Jednym z najpopularniejszych metod generowania liczb losowych o rozkładzie Gaussa jest zastosowanie transformacji Box-a-Mullera. Dla dwóch, niezależnych zmiennych losowych \(x_1,x_2\), o rozdkładach jednostajnych na odcinku (0,1) obliczamy:
\[y_1 =\sqrt{-2 \ln x_1} \cos(2 \pi x_2)\,\] \[y_2 = \sqrt{-2 \ln x_1} \sin(2 \pi x_2).\,\]
Zmienne losowe \(y_1,y_2\) mają rozkład Gaussa o średniej zero i odchyleniu jeden i są statystycznie niezależne.
Można to pokazać korzystając z reguł transformacji zmiennych losowych. Najpierw obliczamy transformację odwrotną:
\[x_1 =\exp{ -\frac{1}{2} (y_1^2 + y_2^2)},\] \[x_2 =\frac{1}{2 \pi}\arctan \frac{y_2}{y_1}\]
a następnie Jakobian \(|\frac{\partial(x_1,x_2)}{\partial(y_1,y_2)}|\), który wynosi:
\[|\frac{\partial(x_1,x_2)}{\partial(y_1,y_2)}|=|{\begin{vmatrix} {\partial x_1 \over \partial y_1} & {\partial x_1 \over \partial y_2} \\ {\partial x_2 \over \partial y_1} & {\partial x_2 \over \partial y_2} \end{vmatrix}}|= \frac{1}{2 \pi} e^{-y_1^2/2} \frac{1}{2 \pi}e^{-y_2^2/2} \].
Ponieważ wynik jest iloczynem funkcji zmiennej \(y_1\) i \(y_2\) to zmienne te są statystycznie niezależne i każda z nich ma rozkład normalny \( \frac{1}{2 \pi}e^{-y_2^2/2}\).
Przykład numeryczny
Bezpośrednio z powyższych wzorów z dwóch wektorów liczb losowych o rozkładzie jednostajnym (x1,x2) wyliczamy dwa wektory o niezależnych rozkładach gaussowskich.

hist(y1,[-10:1/10:10],10) hold on fplot(@(x) normpdf(x),[-5,5],"r-*") hold off
N=30000 x1=rand(N,1); x2=rand(N,1); r = sqrt(-2.0 * log(x1)); phi = 2.0 * pi * x2; y1 = r .* cos(phi); y2 = r .* sin(phi); plot(y1,y2,'.')
Niezależność statystyczną możemy sprawdzić funkcją kowariancji
cov(y1,y2)
która powinna dążyc do zera dla rosnacych wartości \(N\).
Własności statystyczne wektorów y1 i y2 można sprawdzić korzystając z:
mean(y1) mean(y2) meansq(y1) meansq(y2)
i można spodziewać sie średnich odchyleń dążących do zera dla rosnących \(N\) oraz średniego odchylenia kwadratowego dążącego do jedności w tej samej granicy.

plot(y1,y2,'.')